

Possibilities Unlimited
Possibilities Unlimited
XtractEdge, so you can harness Insights Unlimited
XtractEdge delivers insights from enterprise documents to make better decisions. As organizations shift from simply surviving in a digital era to thriving in a digital world, the business opportunities for enterprises that can extract value from their data have never been greater.
XtractEdge, the Document AI platform, provides you a powerful tool to gain insight from documents; legal contracts, commercial insurance papers, SOPs, images, handwritten notes, PDFs, emails, or any other document. Enterprises can now unlock unlimited possibilities by gleaning insights from myriad unstructured data to deliver measurable business value.
XtractEdge helps clients capitalize on the inherent power of a connected enterprise by amplifying human potential, crafting connected customer journeys, and exploiting the power of value networks.
10x
Productivity improvement for an American Bank
98%
Clause extraction accuracy for a Telecom Major
90%
Cost reduction for a Fortune 500 Conglomerate
$90M
Revenue leakage opportunity identified for a Telecom Major
Solving Enterprise
Document Problems
Solving Enterprise Document Problems
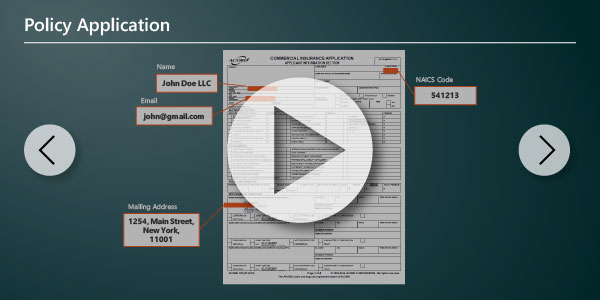
Extract intelligence from structured or unstructured enterprise documents, regardless of template or layout complexity or domain specificity.

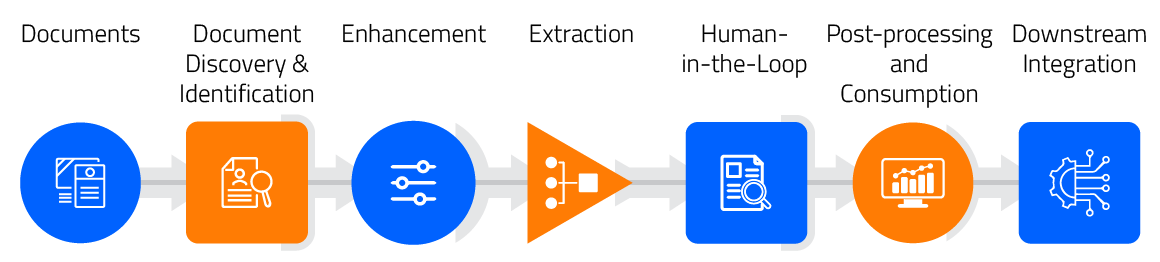
End-to-End Document Processing with XtractEdge Platform
End-to-End Document Processing with XtractEdge Platform
Business Value Unlocked
Business Value Unlocked
XtractEdge Platform optimizes the document extraction, processing, and comprehension pipeline to help enterprises unlock business value faster.

Improve Productivity

Improve Time to Value

Improve Decision Making
The XtractEdge Platform Difference
The XtractEdge Platform Difference

Auto-discovery of documents
Fast onboarding of new layouts,
variants

Integrated measurement and quality benchmarking
Platform and Products
Platform and Products

XtractEdge Platform
Extract intelligence from enterprise documents, regardless of complexity or domain specificity

XtractEdge Commercial Insurance
Accelerate new business intake/processing with domain focused out-of-the-box capabilities

XtractEdge Contract Analysis
Derive insights from contracts and legal documents across industries
Solutions
Solutions
KYC and Customer
Onboarding

LIBOR
Transition
Claims and EoB
Processing

Invoice
Processing
Recognition
Recognition
Gold Award in the Artificial Intelligence category in the 13th Annual 2021 Golden Bridge Business and Innovation Awards
According to IDC survey respondents, EdgeVerve is among the top document AI software/ technologies in use*
Everest Group Intelligent Document Processing (IDP) Products Peak Matrix Assessment 2021
Contender in The Forrester New Wave™, Computer Vision Platforms, Q4 2019
Finalist in AIconics 2020 as Enterprise Solution of the year
Gold Award in the Artificial Intelligence category in the 13th Annual 2021 Golden Bridge Business and Innovation Awards
According to IDC survey respondents, EdgeVerve is among the top document AI software/ technologies in use*
Everest Group Intelligent Document Processing (IDP) Products Peak Matrix Assessment 2021
Contender in The Forrester New Wave™, Computer Vision Platforms, Q4 2019
Finalist in AIconics 2020 as Enterprise Solution of the year
*Source: IDC, What Is the Landscape of the Emerging Document Artificial Intelligence Market?, Doc # US47701421, July 2021
Request a demo

Thanks for your interest!
Our team will get in touch with you soon.