Home > XtractEdge > Blogs > What did the buffalo say to his son when he left for college?
What did the buffalo say to his son when he left for college?

“Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo.” Prof. Pushpak Bhattachararya kick-started our NLP course at IIT Bombay with the ‘buffalo’ sentence. It worked perfectly for him; he could witness our amusement when he declared that it is a grammatically correct statement! Our ways to communicate continue to amuse me at times. As a matter of fact, it is often debated that language played the most important role in human evolution. In this article, I argue that language will also play the pivotal role in evolution of artificial intelligence.
A criteria to determine intelligence? Understanding a language. I am not talking about understanding grammar; that is a simpler task. Grammar is what we collectively, as a society, decide. Language is characteristic not of a society, but of a person. Each individual has a unique way to use and misuse language. That doesn’t form a communication barrier for us, though. Our ability to understand each other is remarkable. Can a machine be trained to have a similar ability?
As I mentioned in my last article, Machine learning has become a synecdoche for Data science; our so-called intelligent machines are limited to making direct inferences from data. Recently, iOS was blamed to be sexist, because when you type-in leadership roles like ‘CEO’, ‘CFO’ or ‘CTO’ using default keyboard, the emoji it suggests will be the default male in a suit. Did it choose to be sexist? It probably just reflects the data from conversations of millions of humans; it doesn’t choose to be good or bad, it only chooses to be like humans. Intelligence is more than this.
Arnold, in HBO’s Westworld, has the notion of a ‘consciousness pyramid’:
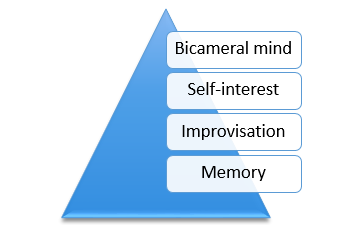
These layers of the pyramid portray the depth of consciousness. It made me wonder, does intelligence have similar depth to it?
Currently, we are working on harmonizing Point-Of-Sales (POS) data. Let me introduce you to my favorite member of our team, we call him Frank. Frank is 2 months old now. He is extremely good at understanding semi-structured sequences of words (To call our inputs as sentences would be incorrect). Why do we call him Frank?
“It’s alive. It’s alive… It’s alive,” – Frankenstein
What makes Frank lively? It is not the tendency to make the same decisions which humans make. We couldn’t settle for that, because we didn’t have sufficient data for supervised learning, and the data which we had has quite a few errors. Harmonization of POS data is simply too difficult and time consuming of a process to be done manually. Frank was initially designed as an unsupervised learner. It started by learning a vocabulary which we created using corpuses like OpenFoodFacts, DBPedia, WordNet, etc. Frank structures its vocabulary as word clusters by guessing the semantic distance of words using word embedding. The second level of learning comes into the picture when a new client is on-boarded; Frank learns the domain of the client depending upon how the client wants its data to be harmonized. Essentially, Frank biases its vocabulary to assign weightages to words as per their importance to the client.
At this stage, we started getting decent results, so we wondered, can we add supervision to it? After few failed attempts using mainstream techniques, we ended up building a layer which mimics survival instinct.
Philosophy of this third layer: “If it saves your life, 2+2=5”. We spawn multiple supervised learners at this level, each one of them aims at surviving consistently in at least one domain. Each of these classifiers behaves like the human notion of ‘stereotypes’ for Frank; each classifier knows how to behave in a particular context. To be precise, each of these classifiers is an over-fit. These classifier have a role similar to weak classifiers in boosting algorithms; difference being that weak classifiers are functionally weak, Frank’s classifiers are partially-trained directional fits. The benefit of using a functionally complex classifier as a weak classifier is that over time and data, it will stabilize to a less weak state, which is not the case with a conventional weak classifier.
How does Frank know which stereotype should be used when? The third level represents the confusion in Frank’s head, and the resolution comes at the fourth level; Frank has to make the ‘choice’. Frank adapts over time to understand which stereotype works better in which scenario. This latter half of Frank is a greedier and cleverer extension of “Random Forests” classifier. Depending on the domain, client, and the quality of feedback given by people who manually verify Frank’s results, classifiers might either be chosen over others, decommissioned, or put in cryosleep until they get better results. Since individual classifiers capture local patterns perfectly, we have simulated Long Short-Term Memory (LSTMs) without explicitly using the construct; Frank remembers local patterns, but the over-fit involved in finding those patterns is balanced with the choice Frank faces in selecting those.
Frank is ready to do his job of harmonization. Is Frank ready to face the world? Not yet. He can do his specific job very well, but the human world and our language has too much creativity for Frank to understand. Frank can understand structure and context, but it is not trained to understand metaphors, similes, sarcasm, etc. Yet, I feel Frank has made an important step in the direction which future generation of intelligent machines will be following.
Let’s end the article hoping that someday Frank will laugh at my geeky buffalo joke:
What did the buffalo say to his son when he left for college? Bison.
Related Blogs All Blogs

Claims process automation: Say goodbye to manual claims processing
March 08, 2023

The need for privacy: Why some data must be kept private, and how Document AI can help
June 07, 2022
Leave a Reply
One thought on “What did the buffalo say to his son when he left for college?”
-
Wow beautiful must read article.
Load more comments...
Mayank Dehgal
Member of Technical Staff
More blogs from Mayank >