Computer Vision
NIA Vision
NIA Vision is an Intelligent capability (AI) which is used as a sub routine in the Process Automation. NIA Vision is a native Computer Vision capability which identifies the object or area of interest within a digital document (pdf) through machine learning (training).
NIA Vision is not an OCR or Advanced OCR capability. In fact, it compliments usage of any OCR or advanced OCR. NIA Vision when combined with OCR tools increases OCR efficiency and reduces the overall effort, cost.
Adding of NIA Vision Application
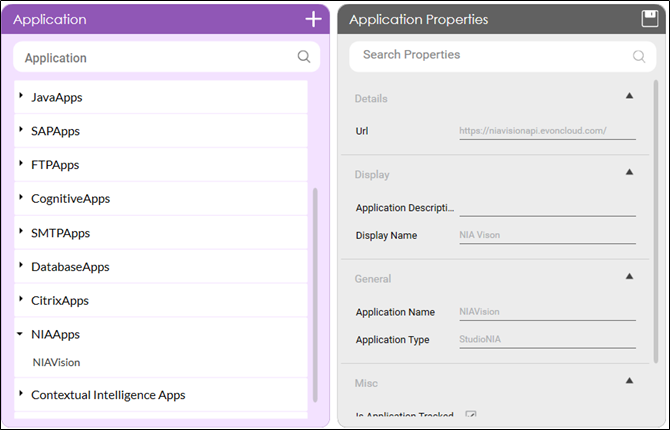
The Studio canvas tools would have NIA Vision activity as the first category of tools. Before using the NIA Vision activity, you need to add the NIA Vision application via Settings (similar to addition of any new application type).
There is a new category of application called NIA Apps where NIA Vision application can be added. There are 2 key parameters needed for using NIA Vision.
- NIA Vision Service URL: It is an EdgeVerve hosted URL, API is called to consume the NIA services.
- NIA Vision Subs key: It is used for authenticated usage of NIA Vision API.
Application parameter requires URL while the subscription key is required for making a call viz – during setup environment and fetching the training models from NIA Vision.
Training
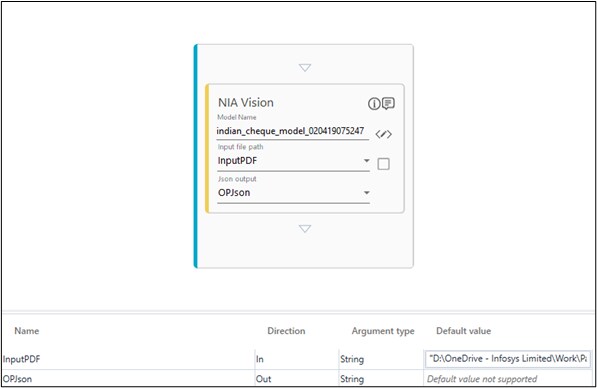
NIA Vision Activity need configuration of 3 things – the model name, the input file path (pdf) and the mapping of the output (which is a JSON).
Let us take an example to move ahead with. You have to apply NIA Vision to different bank cheques. The input pdf file has one or more cheques and the process automation (use case) needs the following fields from each cheque – Date, Payee, Cheque No., Amount.
The NIA Services team is involved to perform training on sample documents to create a training model. This model can identify the above 4 fields in a cheque. Ideally, sample documents for training need 5-10 samples for each variation. Example: 5-10 samples for each cheque variation for the banks in consideration. Some cheque objects may have old structure, some may have new, some may be colored, some may be black and white, some with noise, some with different widths and so on. Whether these samples occur in 3-4 or a single document is immaterial.
NIA Workbench is used to upload the training documents, tag and create a suitable training model for the use case (with desired model accuracy) which suffices the business need.
The complete training process is part of NIA Vision services implementation.
The output of the training is a training model with a user defined name. The same name (model name) will be needed in the Studio which would be applied on any new incoming pdf of cheques or a respective file.
Model Selection and Configuration
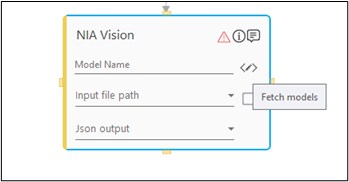
Once you have the details of the training model name, you can click the fetch models button, enter the subscription key and fetch the models. A call is made to NIA Vision services and the available training models will be auto populated in a list below. You can choose the respective training model which needs to be applied for the input file.
The input file is a pdf file and the output parameter is a JSON in a string format. This argument will be an OUT type argument.
NIA Vision Activity Properties - NIA provided OCR
There are certain key parameters as part of the NIA Vision activity properties which can be configured for advanced usage.
- DPI: Using this property, you can throttle the max DPI for the file image processing.
- NIA Request ID: Every NIA Vision service call has a request ID. Using this property, you can track NIA Vision requests (if needed) by mapping it to an argument label in Studio.
- Use NIA OCR: NIA Vision has an ability to apply OCR (free Tesseract in 18.0) to the identified object (Payee for example in a cheque). For using this ability, you need to (ask the NIA services team) enable this option by creating a label for OCR (along with regex if needed) for each object. After that, when you click on use NIA OCR, you will be able to consume the OCR value of the object from NIA. In most cases, you may not use this OCR as you will rely on Advanced OCRs (MS, Google, Abbyy) where you would combine NIA + Advanced OCRs.
Output Consumption
The NIA Vision JSON output has the following key values:
- Object Label – This is the identification by the NIA Vision for the object (Payee, Date, Cheque No. and Amount).
- Object Bounding Box – Each identified object will have four co-ordinates to mark that object (Xmax, Ymax, Xmin, Ymin). These are pixel co-ordinates.
- Object Confidence score – Ranging from 0 to 1, this is a normal distribution confidence. 0.89 = 89% confidence of the NIA Vision machine learning model that what it has identified is the respective object.
- NIA OCR text value in the predefined label.
The JSON activity in Studio can be used to extract each of the key values from the NIA Vision output. For multiple iterations (most of the times), Advanced Loop is used to iterate over JSON (Loop within a loop). Thus you will be able to get the values for all identified objects in a key value pair format in respective predefined arguments.
PDF to Image for using any other OCR
In many use cases, you need to use NIA Vision for data classification and MS Advance OCR or any other OCR for data extraction. Because NIA Vision reduces the data extraction area and hence increases the efficiency of OCR. The PDF to image activity helps for the same. It understands the pdf and the objects within the pdf through the NIA Vision bounding box and produces images as output only for those bounding box objects. These object images can then be passed to any OCR for extraction.
Exception Management with NIA Vision
When working with NIA Vision activity, the following techniques can be used for managing exceptions:
- Using Confidence Score: Confidence Score can be used for rejecting an object if the score is too low, selecting amongst multiple objects of same type.
- Try Catch and Regex validations.
- Routing failure cases to other sub routine processes.
|
NOTE: |
Data classification and Data extraction without template is an approach where even if the Studio configuration has 100% accuracy, the approach should be to automate the process incrementally at runtime. There is a need to setup a separate process for validation of extracted data before decision making. |